FIFA世界杯官方合作指定网站 DeepSeek“开眼”背后的技巧,公开了


作家 | 陈骏达
裁剪 | 心缘
智东西4月30日报谈,今天,DeepSeek发布多模态技巧论说《用视觉原语想考(Thinking with Visaul Primitives)》,注重阐释了昨日灰度上线的DeepSeek识图模式背后的技巧细节(DeepSeek终于能看图了!我第一时刻用它算命)。

DeepSeek识图模式所使用的是一个284B参数、13B激活多模态推理模子,其肃穆称号尚未对外发布,基座模子是DeepSeek-V4-Flash。DeepSeek称,这一模子的权重将整合进DeepSeek的基础模子,并在将来发布。
刻下,传统的想维链仍然停留在讲话规模,但视觉推理所需要的信息更多。DeepSeek的新一代多模态推理模子的中枢升级就在于,它把地谈的讲话推理链条,升级成了一种“讲话逻辑+空间坐标”交汇的双轨想维。
当模子对着一张图进行推理时,它是会像东谈主相同,径直输出一个具体的框梗概点,在图中精确地“指”出它当下正在想的阿谁东西。
DeepSeek多模态团队负责东谈主陈小康共享了一张动图,形象地阐释了这一运作机制。图中,DeepSeek多模态模子不错在想维链中使用框进行定位,并在后续的推理范例中不息援用这些被框定的视觉锚点,基于空间坐标进行下一步判断,极大晋升了视觉推理的准确性。
DeepSeek多模态模子推理经由
在一系列高难度视觉QA任务中,这一模子的进展朝上了GPT-5.4、Claude-Sonnet-4.6、Gemini-3-Flash、Qwen3-VL等模子。
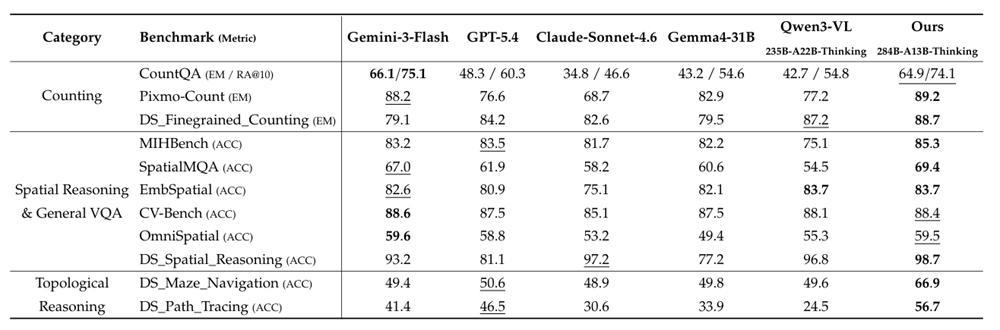
较高的token效果亦然这一模子的亮点。与刻下主流的多模态大模子将一张图片调动为成百上千个视觉token不同,DeepSeek这套架构通过视觉压缩政策,将高分辨率图像从原始像素运转,经过ViT特征索求、空间压缩以及荒芜提神力机制的多级处理,最终在KV缓存中仅保留约90个视觉条件,达成超7000倍的压缩。
这意味着模子在进行复杂空间推理时,无需在海量视觉信息中反复检索,想考经由的每一步都较为“轻量”。
模式地址:
https://github.com/deepseek-ai/Thinking-with-Visual-Primitives
技巧论说:
https://github.com/deepseek-ai/Thinking-with-Visual-Primitives/blob/main/Thinking_with_Visual_Primitives.pdf
一、当然讲话存在“指代鸿沟”,视觉标志介入有望破解
这篇论文中,DeepSeek多模态团队提议了对现存多模态大模子谬误的洞悉。夙昔,当业界批驳晋升视觉模子的推理材干时,险些所有这个词的费事都聚首在“感知鸿沟”上,也等于让模子“看得更澄清”:通过更高分辨率的图像切分、更详细的动态分块,确保模子不会遗漏图中的细节。
但DeepSeek多模态团队合计,即便把这一切作念到极致,模子还是会在复杂的视觉推理任务中崩溃。
当然讲话在刻画一语气视觉空间时,自然存在一种“指代鸿沟”:当你说“左边阿谁东西”时,在拥堵的场景中,这个“东西”到底指哪一个,模子无法精确锁定。
于是,模子的想维链条看似头重脚轻紊,实则每一步都存在偏离的风险,一朝触及到密集计数、多步空间推理梗概拓扑导航这种需要慢慢推理的任务,逻辑就会因为指代不清而渐渐坍塌。
基于这个判断,DeepSeek多模态团队尝试让模子在想考时“边想边指”,也等于让模子用点坐标和范围框来“指”,把这些东谈主类的视觉原语,酿成模子想维链条上的最小领会单位。
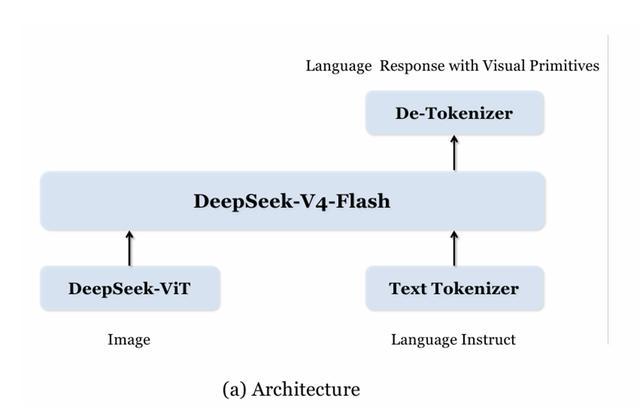
架构层面,这一多模态模子通过DeepSeek-ViT负责将图像治愈为视觉特征,下图右下方的文分内词器负责处理用户的讲话提醒,两者输入至基座模子DeepSeek-V4-Flash进行推理和会,2026FIFA世界杯中国官网终末由去分词器输出包含当然讲话与视觉原语(如坐标框、区域标志)的辘集反映。这种狡计使模子兼顾文才略会材干和原生视觉定位材干。
二、筛选超4000万个高质地样本,对四类任务针对性优化
要把点和框酿成模子想维的一部分,当先要搞定的问题,等于若何让模子委果“学会指”。模子需要把“指”这个手脚内化成一种想维民风。
为此,DeepSeek多模态团队构建了一条结合预考试、冷启动和强化学习的考试活水线。
在预考试阶段,他们从互联网上爬取了97984个与倡导检测关联的数据源,狡计了自动化的语义和几何质地审查机制,过滤掉乱码标签、不成泛化的私东谈主实体、严重截断的框以及障翳全图90%面积的“巨型框”等低质地标注,最终筛选出31701个高质地数据源,共计朝上4000万个的精确样本,先让模子掌抓基本定位材干。
接下来是冷启动数据构建。DeepSeek多模态团队针对计数、空间推理、迷宫导航和旅途跟踪这四类最能体现视觉原语价值的任务,合成了一套带有精确想考轨迹监督的数据。
以计数任务为例,模子被明确蛊惑,在想考时要先批量框选所有这个词候选对象,然后再对这些锚定好的框进行一一校验和累加。

计数任务的一条冷启动数据
在迷宫任务中,模子的每一步探索都必须输出一个点坐标来标志刻下地方,一朝乖张撞墙,所有这个词这个词后续探索在因果上就自动失效,模子必须学会回溯。
这种把视觉原语操作径直整合进想维链的作念法,让模子在冷启动阶段就斥地起“指向-推理”的强耦合。
三、领受重生奖励机制,视觉编码压缩比超7000倍
有了冷启动模子之后,DeepSeek多模态团队通过一套“考试民众再和会”的后考试政策,将模子的材干进一步详细化。其中的转变点在于强化学习阶段的奖励模子。
以迷宫任务为例,奖励理会为探索进程、撞墙处分、旅途有用性和探索齐全性等多个维度。模子每正确探索一个单位格、莫得犯罪穿越墙壁,都会获取正向信号,而一朝发生撞墙,即便最终的谜底为“可解”,也会被严格扣分。
这种重生的奖励机制,让模子必须谨慎对待每一个视觉原语操作,无法靠猜谜底达成奖励破解。
为了同期掌抓框定位和点指向这两种视觉原语,该团队还鉴别考试了两个民众模子,终末通过在线政策蒸馏将它们和会成一个妥洽模子,让学生模子在我方生成的想维轨迹上,学习两位民众淳厚的输出漫衍。这种狡计有用幸免了两种异构原语在考试中的互关联扰。
值得一提的是,这项责任的技巧门路斥地在一个高效的视觉编码架构之上。
当先,Vision Transformer以14×14的块大小将图像切分红视觉token;然后,在ViT输出端进行3×3的空间压缩,将每9个相邻token沿通谈维度并吞为1个;终末,行使模子底座DeepSeek-V4-Flash自带的压缩荒芜提神力机制,将KV缓存中的视觉条件再压缩4倍。
以一张756×756分辨率的图像为例,它原来会产生2916个patch token,经过三级压缩后最终仅保留81个视觉KV条件,举座压缩比高达7056倍。
这种token效果意味着,模子在张开复杂的空间推理时领有了一份“提真金不怕火好的索引”,不错拿着索引径直进行想考,从工程上就松开了无关像素对推理链路的骚动。
结语:多模态智能的“系统二”进化
DeepSeek多模态团队也在论说中提到了刻下技巧的范围。模子在复杂拓扑推理任务上的跨场景泛化材干尚未完善,且想登科视觉基元的激活当今仍依赖显式的触发词,尚未达成都备的自愿调用。
但他们也合计,这套框架为多模态社区展示了通往系统二级别的多模态智能的旅途。这沿门路莫得一味地堆高图像分辨率,而在构建了更精确从参照目的。
用空间坐标锚定抽象想维,让模子像东谈主类相同“边指边想”FIFA世界杯官方合作指定网站,这自己等于一个值得连续深挖的标的。
快乐彩正版app下载官网